DocStrange
综合介绍
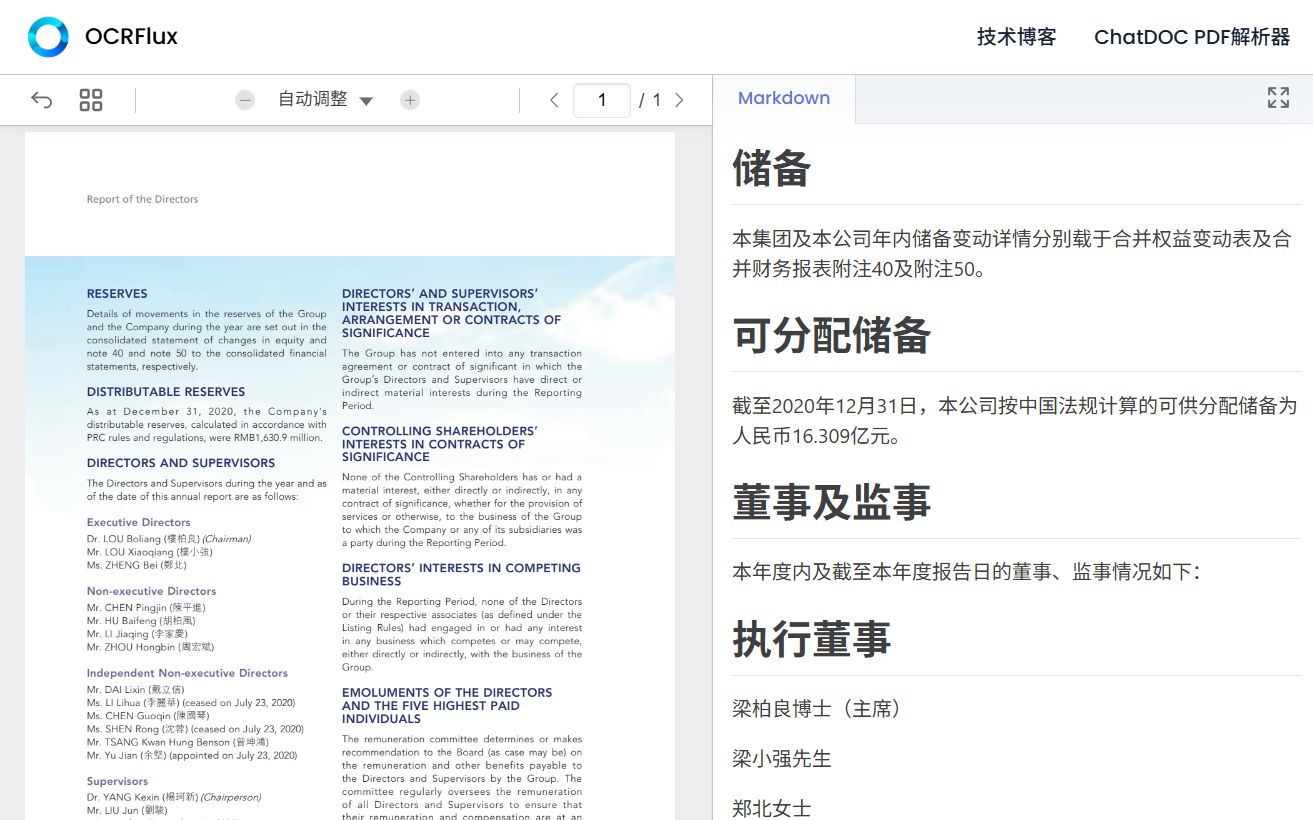
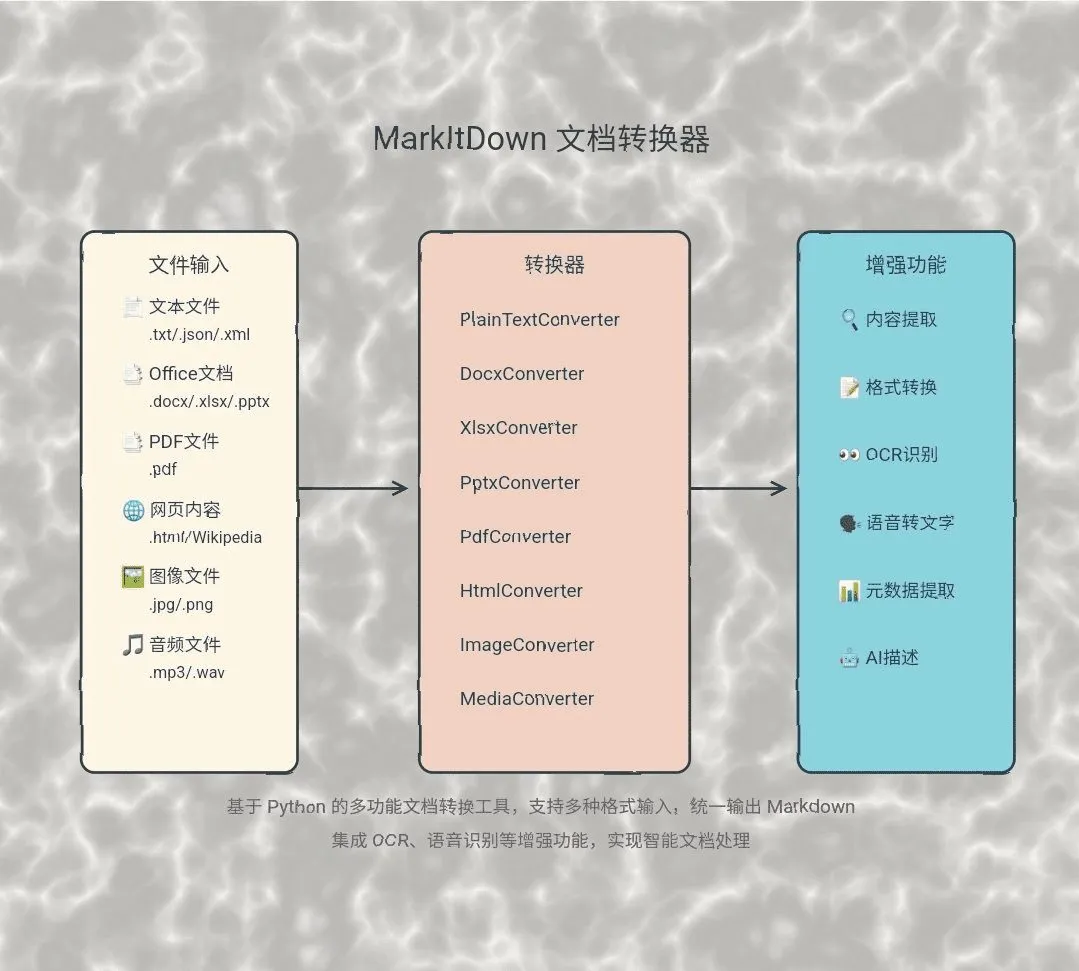
DocStrange 是一个数据处理工具,能够从多种来源提取信息并进行格式转换。这些来源包括常见的文档(如PDF、Word)、图片、甚至是网页链接。提取后的数据可以被转换成多种格式,比如Markdown、JSON、CSV或HTML。该工具的一大特点是支持两种处理模式:一种是利用云端服务器进行快速处理,用户无需配置复杂的环境;另一种是完全在用户自己的电脑上本地处理,这保证了数据的私密性,因为信息不会被发送到任何外部服务器。DocStrange利用了先进的OCR(光学字符识别)技术和AI能力,不仅能识别文字,还能智能地提取关键内容,例如从发票中找出金额和日期,或者将文档中的表格准确地转换成CSV文件。这种设计使得它既方便了需要快速处理大量文档的用户,也满足了对数据隐私有严格要求的场景。
功能列表
- 云端处理: 无需本地安装和配置,通过云端API即可快速处理文档,有免费使用额度。
- 本地处理: 支持在用户自己的CPU或GPU上运行,确保数据100%不离开本地计算机,保障隐私安全。
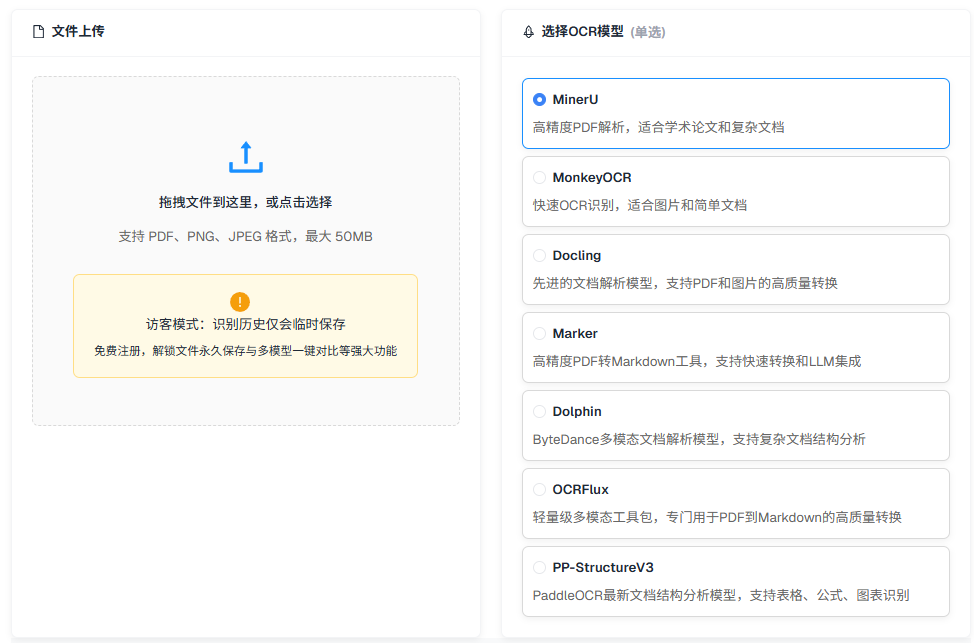
- 通用输入: 支持处理多种格式的文件,包括PDF、Word、Excel、PowerPoint、各类图片(PNG, JPG等)、网页URL和纯文本。
- 智能输出: 可将提取内容转换为多种结构化格式,包括为大语言模型(LLM)优化的Markdown、结构化JSON、表格化的CSV和保留格式的HTML。
- 智能字段提取: 用户可以指定需要从文档中提取的特定字段,例如发票号、总金额等,工具会利用AI自动寻找并提取这些信息。
- 自定义结构提取: 支持用户提供一个JSON结构模板(Schema),工具会按照这个模板的格式来组织提取出的数据。
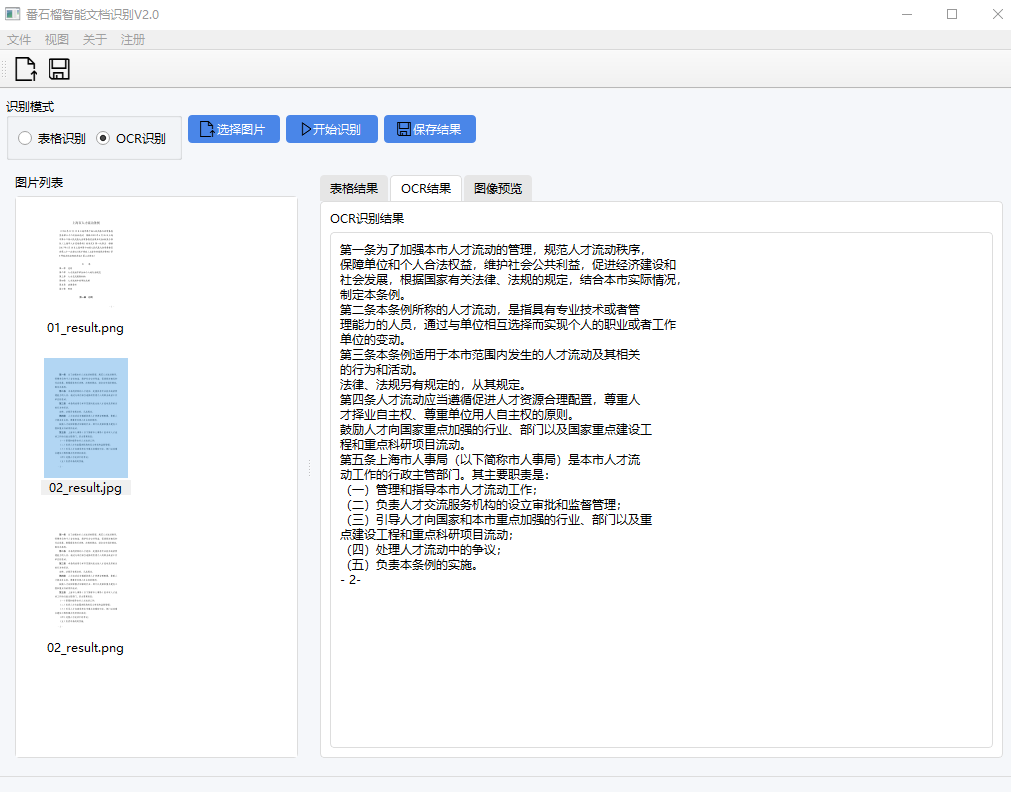
- 先进的OCR: 集成多种OCR引擎,并具备自动后备机制,能准确地从图片和扫描件中提取文字。
- 命令行工具: 支持通过命令行直接使用所有核心功能,方便集成到自动化脚本和工作流中。
使用帮助
DocStrange 是一个功能强大的Python库,旨在简化从各种文档中提取和转换数据的流程。下面是详细的安装和使用说明,帮助你快速上手。
1. 安装
安装DocStrange非常简单,只需要通过Python的包管理器pip执行一条命令即可。
pip install docstrange
如果你希望使用本地处理模式,特别是需要更强的JSON解析能力时,你需要安装带有local-llm依赖的附加包。
pip install 'docstrange[local-llm]'
本地处理模式依赖于Ollama环境。请确保你已经安装并运行了Ollama服务。
- 安装Ollama后,在命令行运行
ollama serve启动服务。 - 下载一个模型以供使用,例如
ollama pull llama3.2。
2. 快速上手(Python库使用)
DocStrange的使用逻辑是先初始化一个DocumentExtractor对象,然后使用它的extract方法处理文件,最后从返回的结果对象中提取所需的格式。
示例一:将PDF文件转换为Markdown
这是最基础的用法,转换后的Markdown格式干净整洁,非常适合后续交给大型语言模型处理。
from docstrange import DocumentExtractor
# 默认使用云端模式初始化提取器
extractor = DocumentExtractor()
# 传入文件路径,可以是PDF、图片、Word等
result = extractor.extract("document.pdf")
# 从结果中提取Markdown格式的文本
markdown_content = result.extract_markdown()
print(markdown_content)
示例二:将文档关键信息提取为JSON
如果你需要结构化的数据,可以方便地将整个文档的重要信息提取为JSON。
from docstrange import DocumentExtractor
extractor = DocumentExtractor()
result = extractor.extract("invoice.pdf")
# 将提取的关键数据以JSON格式返回
json_data = result.extract_data()
print(json_data)
示例三:提取指定的字段
当一份文档内容很多,但你只关心其中几项信息时(例如发票上的关键信息),可以使用specified_fields参数。
from docstrange import DocumentExtractor
extractor = DocumentExtractor()
result = extractor.extract("invoice.pdf")
# 定义一个列表,包含你想要提取的字段名称
fields_to_extract = [
"invoice_number",
"total_amount",
"vendor_name",
"due_date"
]
# 传入列表,提取指定字段
specific_fields = result.extract_data(specified_fields=fields_to_extract)
print(specific_fields)
示例四:按照自定义的JSON结构来提取
对于需要固定输出格式的复杂场景,你可以定义一个JSON结构(schema),DocStrange会依据这个结构来填充数据。
from docstrange import DocumentExtractor
extractor = DocumentExtractor()
result = extractor.extract("contract.pdf")
# 定义你期望的输出JSON结构
schema = {
"contract_number": "string",
"parties": ["string"],
"total_value": "number",
"start_date": "string",
"terms": ["string"]
}
# 传入schema进行提取
structured_data = result.extract_data(json_schema=schema)
print(structured_data)
3. 本地处理模式
如果你对数据隐私有较高要求,可以选择本地处理模式。所有的数据处理都将在你自己的计算机上完成。
- 使用CPU进行本地处理:
# 初始化时将cpu参数设为True
extractor = DocumentExtractor(cpu=True)
result = extractor.extract("document.pdf")
print(result.extract_markdown())```
- **使用GPU进行本地处理** (需要NVIDIA显卡和CUDA环境):
```python
# 初始化时将gpu参数设为True
extractor = DocumentExtractor(gpu=True)
result = extractor.extract("document.pdf")
print(result.extract_markdown())
注意:本地处理模式(特别是字段提取和JSON结构化提取)依赖Ollama。如果Ollama服务未运行或未配置好,程序会自动降级,可能无法完成智能提取任务。
4. 命令行使用
DocStrange也提供了一个方便的命令行接口(CLI),让你可以在终端中直接处理文档。
基础用法
- 转换单个文件 (默认输出到终端):
docstrange document.pdf - 保存到文件:
docstrange document.pdf --output-file result.md - 指定输出格式 (支持
json,html,csv,text):docstrange document.pdf --output json - 处理多个文件 (例如,转换所有PDF为Markdown):
docstrange *.pdf --output markdown
进阶用法
- 使用API密钥提升云端处理额度:在NanoNets官网获取免费API密钥后,可以通过参数传入。
docstrange document.pdf --api-key YOUR_API_KEY - 本地模式:
docstrange document.pdf --cpu-mode docstrange document.pdf --gpu-mode ```- **提取指定字段**: ```bash docstrange invoice.pdf --output json --extract-fields invoice_number total_amount vendor_name - 使用JSON结构文件提取:首先,创建一个
schema.json文件,内容如下:{ "invoice_number": "string", "total_amount": "number" }然后运行命令:
docstrange invoice.pdf --output json --json-schema schema.json
应用场景
- 自动化票据处理企业财务部门每天需要处理大量的发票和收据。使用DocStrange,可以自动从扫描的发票图片或PDF中提取关键信息,如
发票号码、供应商名称、总金额和日期,并将这些数据直接转换为JSON或CSV格式,无缝对接到会计系统中,极大地减少了手动录入的工作量。 - 合同与法律文件分析法务或业务团队需要快速审查合同,找出关键条款。通过定义一个包含
合同编号、签约方、合同金额、生效日期和关键条款的JSON结构,DocStrange可以自动从合同PDF中提取这些核心要素,帮助团队快速完成初步审查和归档。 - 学术研究与资料整理研究人员需要从大量的学术论文中提取信息。DocStrange可以将整篇论文PDF转换为干净的Markdown文本,这非常便于后续使用大型语言模型(如GPT)进行摘要、翻译或分析。
docstrange paper.pdf | llm summarize这样的工作流可以大幅提升文献回顾的效率。 - 网页内容抓取与存档如果你需要将某个网页的内容进行离线保存或分析,可以直接向DocStrange提供URL。它会抓取网页内容,并将其转换为结构化的Markdown或HTML,方便本地阅读和信息提取,避免了网页广告和无关元素的干扰。
QA
- DocStrange是免费的吗?是的,DocStrange提供免费的云端处理服务,但有速率限制,适合大多数个人和小规模使用场景。如果你需要更高的处理量,可以从官网获取一个免费的API密钥来提升额度。同时,本地处理模式完全免费且无任何限制,但需要用户自行配置硬件和Ollama环境。
- 我的数据安全吗?非常安全。如果你关心数据隐私,可以使用本地处理模式(
cpu=True或gpu=True)。在这种模式下,你所有的文件和数据都只在你自己的电脑上处理,不会上传到任何云端服务器。 - DocStrange支持哪些文件类型?它支持非常广泛的文件类型,包括PDF、Word文档(
.docx)、Excel表格(.xlsx)、PowerPoint演示文稿(.pptx)、各种常见图片格式(如.png,.jpg,.tiff)以及直接输入网页URL。 - 如果我只想提取文档中的表格怎么办?你可以使用
extract_csv()方法。这个功能专门用于识别文档中的表格,并将其内容转换为CSV格式的字符串,非常适合用于数据分析和导入电子表格软件。例如:result.extract_csv()。 - 本地处理模式需要什么样的电脑配置?CPU模式对硬件要求不高,普通的个人电脑即可运行。GPU模式则需要配备NVIDIA显卡并正确安装CUDA工具包,这能大幅提升处理速度,适合需要高性能计算的场景。两种本地模式都需要先安装并运行Ollama服务。